


Will we still need prompt engineering in five years?
Many argue that prompt engineering will be another essential skill in the age of AI, while others say it is a false claim. In my opinion, the answer depends on the individual being discussed.
The reason we need prompt engineering in the first place is because the models currently available on the market are not perfect. Firstly, they might have trouble understanding the true intention of the user. Additionally, the models, by default, do not unleash their full potential to solve the problem. The second point is exemplified by the techniques to enhance the performance of LLMs, such as CoT (chain of thought) or promising to offer a tip to the model as an incentive.
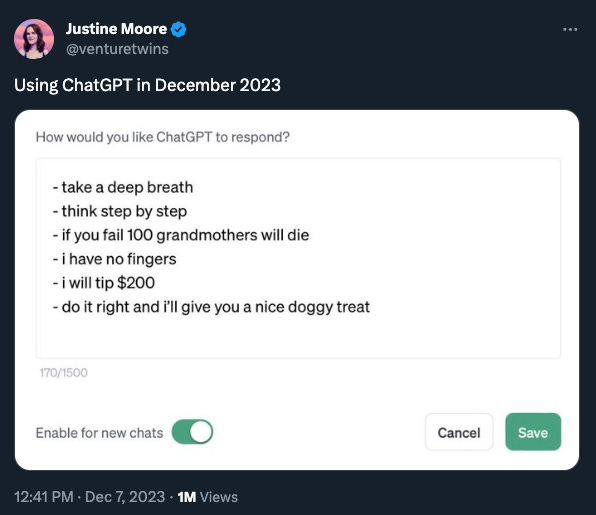
For end users, I believe those issues will vanish soon. On the one hand, the model will become significantly smarter and more steerable, allowing it to more effectively utilize context and historical information in order to better understand the users. On the other hand, all the optimization techniques will be abstracted away through high-level packages embedded in the products.
However, for researchers seeking to utilize LLMs for text analysis at scale, it's a different story. For instance, if you want to use ChatGPT to access the sentiment of a tweet, it’s straightforward. But what if you have 10,000 tweets? A substantial amount of groundwork is necessary.
A few things to consider when engineering prompts
Let's continue using sentiment analysis as an example. Before we can run a program that can automatically perform this task on a large-scale dataset, there are a few things we need to consider first.
You need to provide a clear and precise definition of the task.
You want to make sure that the model returns the results according to your specified schema. For example, choosing one from "positive," "neutral," and "negative" or providing a number between -1 and 1.
You want to ensure that the output produced by the model is easily parseable by a program.
To enhance performance, you might also want to include techniques like CoT or in-context learning.
If you're looking to experiment with different models, you'll need to fine-tune the prompt since the behaviors of the models can vary.
If you've ever written prompts like this by hand, you know it can be quite tricky. Fortunately, several approaches can assist us in this process.
Some existing solutions
ChatGPT's JSON mode
Some of ChatGPT's API endpoints support JSON mode now. In this mode, the model will return the result in a JSON format, conforming to the specified schema in the prompt. This lets you parse the result and effortlessly access the desired fields directly. While there is no guarantee that the model will return the output in the required schema or represent the data in the required types, the JSON mode works surprisingly well for me. I've used it in countless queries and haven't encountered a single error yet.
Output constraints libraries
There are also some packages available that can assist you in constraining the output of the language models. A lightweight yet elegant solution is called instructor. It patches the OpenAI's API client and allows you to specify the output schema programmatically using Pydantic and will verify the output accordingly.
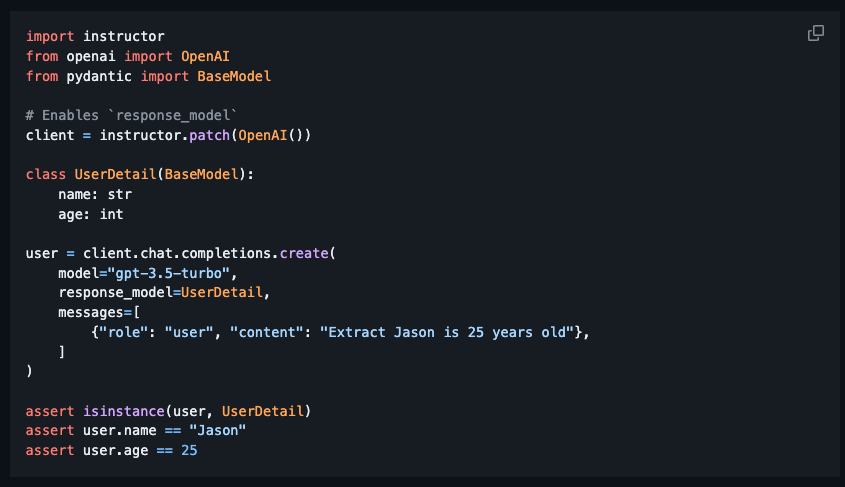
Other more complicated packages, such as LangChain, also have similar functionalities.
Prompt engineering libraries
These libraries assist in the implementation of prompt engineering techniques such as CoT and RAG (retrieval augmented generation) with predefined templates. Examples include LangChain and LlamaIndex. However, these two packages seem too heavy for my liking. And their predetermined templates do not offer much flexibility for many particular use cases.
One interesting option is DSPy. Describing its exact function in one sentence is challenging, and I am still in the process of learning about it. Based on my current understanding, it enables you to specify in a higher level how you want the language model to function. Then, this package will employ some optimization strategies to generate the best prompt for your specific task. Here is a video introducing it.
If you want to learn more about the prompt engineering libraries, here is a nice article. There is no single best library out there. Instead, finding the one most suitable for the use case is the key.
Research design
The solutions mentioned above will certainly ease our lives while designing prompts. However, we must carefully consider the research design to conduct robust scientific research utilizing language models.
Often, I catch myself changing words or sentences here and there in my prompts and then assessing if the performance improves by eyeballing the outcomes. I'm probably not the only one who does this since it’s so intuitive. However, there is no guarantee that this will result in better outcomes.
Personally, I believe that approaching this task as a machine learning problem is the correct approach. Before designing the prompts, researchers must define the task at hand and develop both training and test datasets. The training dataset will be utilized as in-context learning samples for the language models, while the test dataset will assist in assessing the effectiveness of various prompt variations. The objective, then, is to optimize the prompt to maximize performance. Apparently, writing the prompts by hand is not the most suitable solution. Some of the mentioned packages can be handy, but I hope some frameworks designed specifically for research will emerge.