
Topic modeling with LLMs
Better clustering and interpretability


Depending on your background, you might still be using LDA or STM for topic modeling in your research. However, as we approach 2024, it's time to explore what the "future" holds in this domain.
Before delving into the details, I want to mention that despite the title's emphasis on LLMs, this post will encompass a broader range of text analysis methods, particularly those based on transformers. My focus here will be on overarching concepts rather than the intricacies of these methods, and I'll try to provide links to readily usable packages.
Enhancing LDA-like methods

The figure above is from our 2022 paper, where we employed STM to discern topics within a Twitter corpus. Frankly, I find interpreting these “bag of words” topics challenging.
In 2023, a straightforward enhancement is to utilize LLMs, such as ChatGPT, to assist interpretation. I heard this idea at a conference but can’t find the reference. However, it’s really straightforward. I selected three topics from the figure above and solicited ChatGPT's assistance in interpretation, and you can see the results in the figure below.

While the reliability of this approach is debatable, I find the generated sentences more coherent than mere word clusters. However, this method doesn't fully exploit the capabilities of modern language models. At its core, it still relies on simple statistical models and overlooks the semantic relationships between words. So, what are the alternatives?
Composite approach
Recent research has proposed various end-to-end topic modeling methods using neural networks. A particularly notable development is the BertTopic project. It’s not a single method but rather a framework comprising multiple modules. It splits topic modeling processing into two phases: document clustering and topic extraction. Unlike LDA-based methods that perform these tasks simultaneously, different phases in BertTopic are distinct, allowing the integration of different models, including LLMs, at each step.
Document clustering
This phase groups documents with similar topics. Modern embedding techniques that leverage pre-trained language models like those from OpenAI or available on HuggingFace shine here. You can also fine-tune or develop your own models. These embeddings, trained on extensive data, effectively capture semantic meanings and can be multilingual.
Once you obtain the document embeddings, clustering methods like HDBSCAN or k-means can be used to create clusters of thematically similar documents.
It’s worth mentioning that although these steps appear straightforward, users must pay attention to the details in practice to ensure the quality of the output. Choosing the embeddings, clustering methods, and parameters can be tricky.
Topic extraction
Once the document clusters are obtained, the next step is to distill topics from each cluster. One can use traditional methods to identify keywords per cluster or leverage LLMs to generate more readable topics.
Intuitively, the latter approach might yield more readable results. However, due to the limited context window of current LLMs, users might need to select a few representative documents from each cluster as the input for LLMs. One simple way to do this is to choose the top k documents nearest to the centroid of the cluster's embeddings. But one can devise other more complicated approaches to ensure the representativeness and diversity of the selected documents.
BertTopic
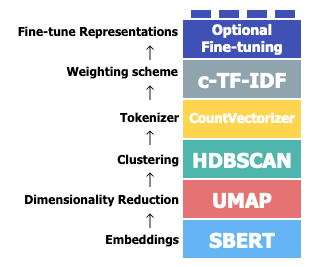
I want to mention BertTopic again, as it turns the aforementioned pipeline into an accessible package. It also allows for combining various models at different stages, offering significant flexibility.
Fully embracing LLMs
Given the extraordinary capabilities of LLMs, an exciting direction is to fully leverage them for topic modeling, exemplified by the TopicGPT paper.
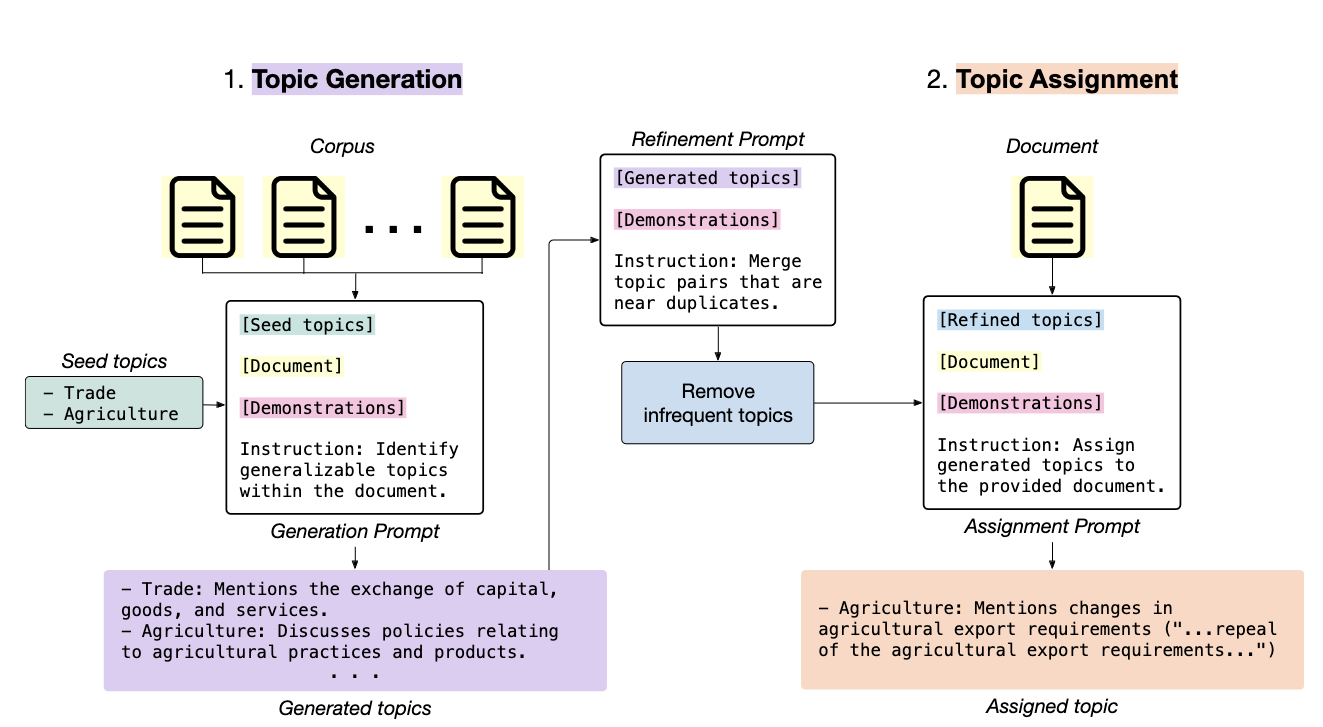
The process is bifurcated into two phases: “topic generation” and “topic assignment.” First, LLMs are fed seed topics to generate specific topics while reading all documents. These seed words, often high-level concepts, can guide the LLMs in the reading. Then, LLMs are employed again to refine and merge similar topics. In the “topic assignment” phase, LLMs read the documents again and categorize them under these topics.
This method's advantages include producing instantly readable results and allowing easy, customizable implementation using LLMs. Moreover, the authors claim that TopicGPT yields superior outcomes.
However, challenges exist. For instance, effective topic generation requires advanced models like GPT-4, while topic assignment can be executed with models like ChatGPT-3.5. The financial cost of API queries can be prohibitive. The experiment in the paper that contains over 14k Wikipedia articles costs over $100. That said, I wonder if one can combine the topic generation and assignment processes together to reduce the number of queries. This would require some careful processing during the topic refinement process.
Another issue is that it's hard to quantify the association of the documents with the topics as the classical methods can do. I tried to ask ChatGPT to give numbers on the association, but it was not very successful. And this could limit its application in some analyses.
Last but not least, prompting LLMs to perform the tasks as desired is tricky. I actually ran some experiments myself using ChatGPT to assign research papers to different topics, and the results are mixed. This means that it might be hard to standardize the best practice of using LLMs for topic modeling. And users will need to adjust the prompts based on their cases every time.
Despite all the limitations, I think TopicGPT still gives us a lot to learn from and think about. The code is publicly available, which can be a good starting point if you are interested in this line of research. They have implemented some effective prompt engineering techniques, such as in-context learning, as detailed in OpenAPI’s prompt engineering guide.
Final remarks

I have been thinking about writing something about content analysis since I returned from the New Directions in Analyzing Text as Data (TADA) conference. It’s a nice gathering of researchers from different disciplines who are passionate about text analysis.
During the conference, I met Chau Minh Pham, the author of the TopicGPT paper, and shared a ride with Brandon Stewart, author of STM, on our way back to Boston. So, I had a chance to talk to them about text analysis. Moreover, I have seen many projects focusing on text analysis using different methods at the conference, including those using classical approaches and those exploring the capability of LLMs in different contexts.
Clearly, we are in a transition period with excitement but no consensus on future direction. However, I foresee two trends:
LLMs eating up everything
I think there is no point in studying or using LDA-based methods anymore. In the short run, the composite approach is practical enough for applications. In the long run (this might mean a few months, given the rapid advancements in the whole AI field), LLMs will inevitably dominate content analysis.
The model capability and cost issues will diminish shortly. Remember, it’s only one year after the release of ChatGPT-3.5, and we already have open-source models with similar capabilities that can run on desktops. Maybe in a few months, we will have GPT-4 level models that are almost free.
Back to TopicGPT, I think it marks a promising beginning, but it’s not the final solution. If you revisit the general idea of TopicGPT and replace “LLMs” with “research assistants” in the pipeline, you will find that it still makes sense. Now, imagine you have access to unlimited research assistants (i.e., free GPT-4), and you have some text to analyze. Will you still ask them to perform topic modeling? Wouldn’t having them directly answer your research question based on the text be great? In that scenario, the assistants will figure out the steps to address your questions, execute them, and then report back to you. Now, that is the idea of generative agents.
For researchers interested in improving techniques on content analysis, the right questions are not how to improve topic modeling. Instead, think about how to create a standardized framework that fully leverages the text understanding and reasoning capability of LLMs to address research questions.
Multimodal Analysis
Although this whole blog is about text analysis, it’s time to think about multimodal analysis. The recently released GPT-4V has demonstrated impressive capabilities in understanding images, and if you provide it with snapshots of videos, the model can also understand videos to some extent. The Gemini-pro, on the other hand, was trained on multimodal data directly. Rumor on the streets is that GPT-4.5/5 is also multimodal.
The multimodal nature of these AI models might provide a unified approach to analyzing visual and audio data together with textual data. However, the rich information embedded in the visual and audio data requires new analytical frameworks. And how to incorporate the advanced AI models into the processes is an interesting yet challenging topic.