


Today, I discovered a GitHub repository where the author demonstrates the innovative use of a large language model to enhance K-Means clustering. While I have not personally tested this method, the results shared by the author suggest it holds significant promise. The concept is quite interesting, so I wrote it down.
The case study in question involves customer segmentation, focusing on several technical features:
1. Age (numeric)
2. Job: Type of job (categorical)
3. Marital: Marital status (categorical)
4. Education: Education level (categorical)
5. Default: Presence of credit in default (binary)
6. Balance: Average yearly balance in euros (numeric)
7. Housing: Possession of a housing loan (binary)
8. Loan: Possession of a personal loan (binary)
Traditionally, one might apply K-Means clustering directly to this raw data, yielding moderately effective results. However, the novel approach involves integrating a language model into the clustering process. According to my understanding of the code, for each customer, a descriptive string is generated, such as "age: 25, job: teacher, ..., loan: yes." This string is then transformed into a vector by applying a language model. Subsequently, K-Means clustering is performed on these sentence embeddings, resulting in enhanced outcomes.
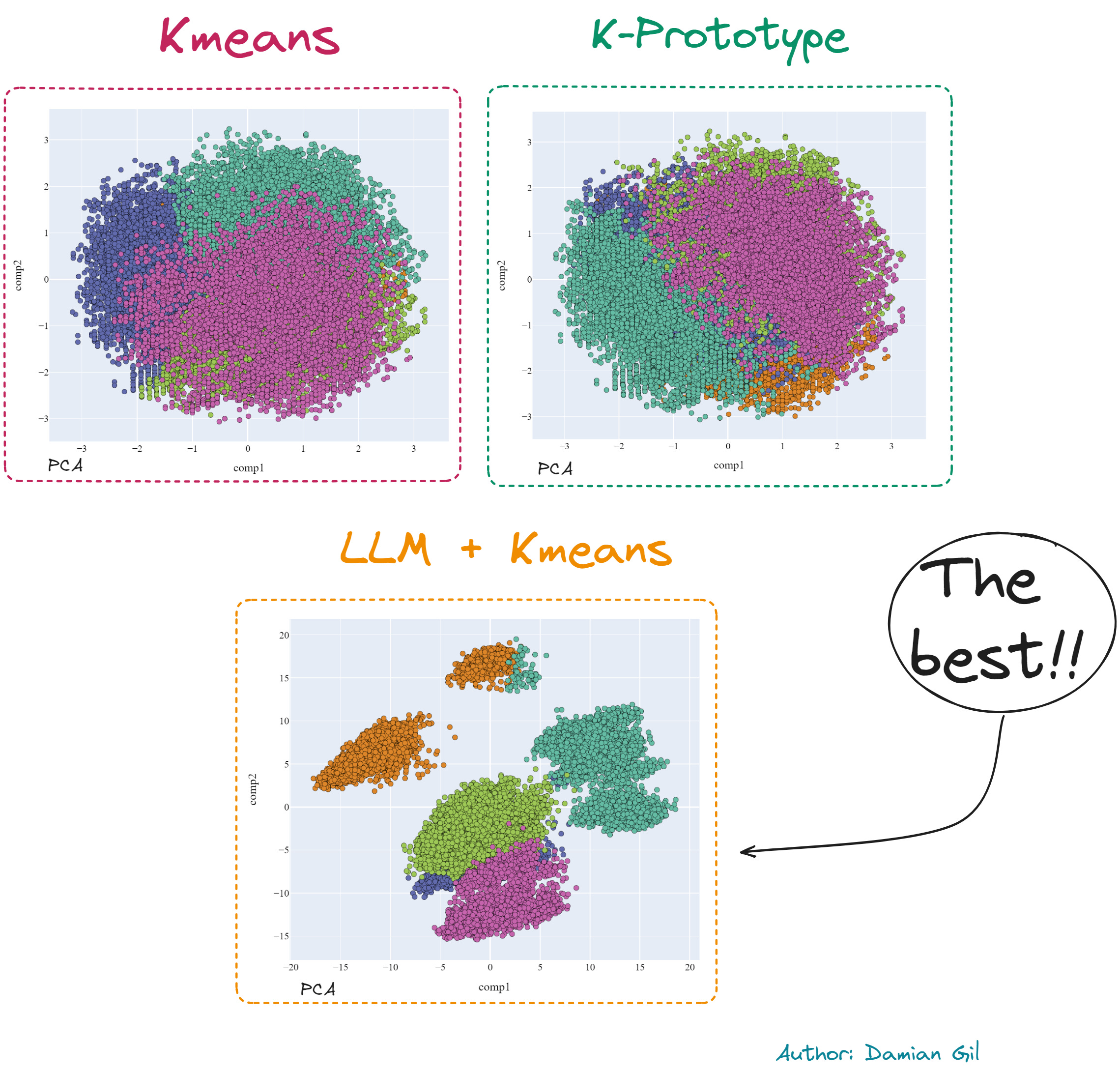
Image from https://github.com/damiangilgonzalez1995/Clustering-with-LLM
This method is particularly fascinating as it appears to leverage the human-centric knowledge encoded in the language model, potentially aiding in more nuanced clustering. However, this technique may not universally apply to all types of tabular data, especially in areas where language models lack training and contextual understanding.
For further reading: