

Inspired by @colin_fraser’s discussion on what LLMs are good for, I’m presenting my mental model.
How LLMs work
Before we dive into my classification, I believe it’s beneficial to revisit the mechanism of LLMs.
To me, the training of LLMs is a compression process where the transformers discover meaningful patterns in the vast amount of training data and then store them as model parameters. The inference of LLMs (i.e., generating new content as requested) is a sampling process based on the learned patterns.
The terms in bold determine what LLMs are good for.
Two factors to consider
Now, we can discuss the factors affecting how well LLMs work.
Since LLMs seek to compress the information and discover patterns from the training data, sufficient samples are necessary. Therefore, the richness of training samples would affect LLMs’ performance on different tasks.
As described above, the inference process involves sampling, meaning noise is inevitable (this is also why hallucinations happen). Therefore, a task’s tolerance to noise is another critical factor.
There is actually a third critical factor. Since LLMs need to learn meaningful patterns from the training data, such patterns need to exist in the first place for LLMs to learn. For instance, LLMs won’t work well on random strings. There is an interesting study on whether LLMs can learn impossible languages.
For simplicity, I will focus on tasks that exhibit meaningful patterns. Consequently, all tasks can be placed on a 2-D plane with two axes: richness of training samples and tolerance to noise.
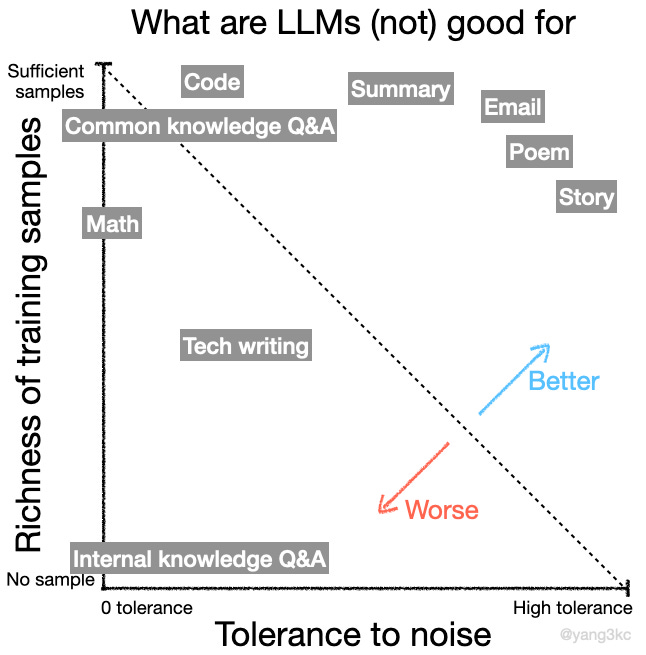
As illustrated, LLMs are, in general, good for tasks located in the top-right corner but not so good for tasks in the bottom-left corner.
Note that the coordinates of the tasks might not be accurate. I placed them based on my gut feeling for demonstration purposes. I will iterate this system as I understand LLMs better.
Now, let’s discuss the example tasks in the figure.
Email, poem, story
I think writing these things is where LLMs shine. The training dataset likely has tons of samples. Also, there are different ways of drafting these types of content, meaning their tolerance to noise is high. When writing poems and stories, noise might even be beneficial as it might make the outcome appear more creative.
Tech writing
Compared with emails, poems, and stories, tech writing (e.g., thesis, court documents, OK, I probably need a better term for this category, but you get the idea) requires more domain knowledge and needs to be accurate on many facts. This leads to fewer training samples and lower tolerance to noise. As a result, LLMs are not very good for this task.
You can still ask LLMs to write for you on very specific topics, and they will produce seemingly legitimate outputs. But be prepared for severe hallucinations.
Summary
I think summary tasks are still quite tolerant to noise and have rich training samples; therefore, LLMs are good for them.
Math vs. code
LLMs are generally bad at math but do OK at coding. What’s the difference here?
Math’s tolerance to noise is extremely low because there is only one correct answer to a given question. At the same time, the training samples might not be sufficient for the LLMs to learn math. There are models, such as Google’s AlphaGeometry, with exceptional performance. However, AlphaGeometry’s success suggests that learning math might require particular model architectures and many high-quality training samples. General-purpose LLMs might never get really good at math.
Compared to math, I think code is more noise-tolerant since there are usually multiple ways to achieve the same goal. Also, the training samples are quite rich. This is why LLMs can code. Another difference is that people often wish LLMs could solve math questions directly, which is difficult. As for coding, LLMs only produce the code; execution is carried out by interpreters. So, one solution to improve LLMs’ math ability is to allow them to use calculators.
Knowledge Q&A
Knowledge Q&A here refers to the situation where the questions have clear answers. The tolerance to noise of these tasks tends to be low, so the performance of LLMs depends on the richness of training samples.
For common knowledge Q&A (e.g., who is the first person to set foot on the moon?), LLMs tend to do well because they are likely trained on the questions and answers already. For internal knowledge Q&A (e.g., how can an employee get reimbursed for a business trip?), LLMs struggle.
Here, I’m just listing some examples on top of my head. I think it’s interesting and useful to consider where a new task is located in the coordinate system above.
When should you use LLMs?
With the classification in mind, it goes without saying that we should avoid using LLMs for tasks they suck at.
But we still need to be careful about the tasks that LLMs are good for. For example, LLMs can write articles to express condolence (rich training samples, high tolerance to noise), but should you use them for this? Probably not.
In the age of AI, the human touch has become more precious than ever.
Fine-tuning & RAG
I listed some tasks that LLMs suck at above, but are there ways to improve LLMs’ performance? Yes! The general idea is to move the tasks from the bottom-left corner to the top-right corner.
Since tasks’ tolerance level to noise cannot be changed, one may consider adding more training samples. This is often achieved through a technique called fine-tuning (training from scratch can be prohibitively expensive), which feeds new training data to the trained models. For example, if you fine-tune an LLM on your internal knowledge database, the model will get better at answering relevant questions. If we go back to the coordinate system, fine-tuning effectively moves the tasks up along the y-axis (illustration below).
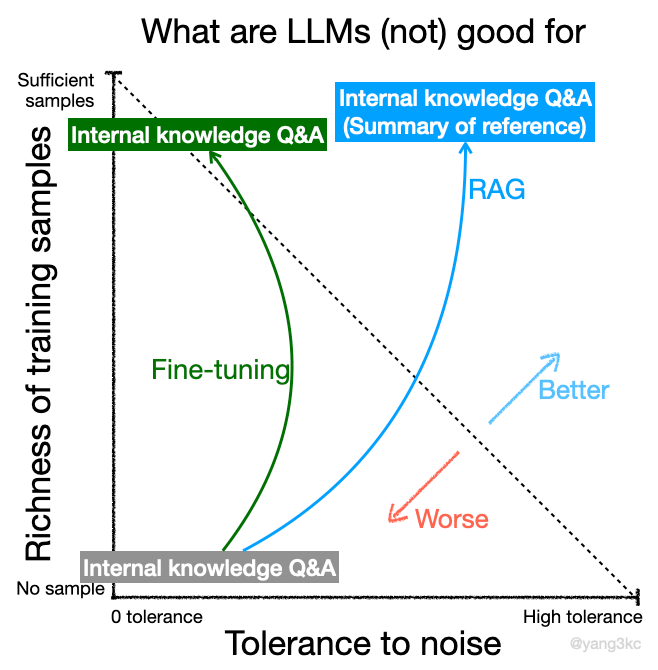
Another technique to boost LLMs’ performce is RAG (retrieval augmented generation). RAG first fetches relevant information from external databases and then uses LLMs to generate answers based on such information. In some sense, RAG turns the original task into a summary task, which LLMs are good for (illustration above).
There are some interesting discussions about the comparison between fine-tuning and RAG, and I plan to write about them later. If you are interested in such topics, be sure to subscribe!