
How to Build an Effective Retrieval Augmented Generation System
No magic here, unfortunately


Disclaimer: I have not personally built a Retrieval Augmented Generation (RAG) system. This article is based on insights gathered from various sources.
What's RAG?
Retrieval Augmented Generation system, or RAG system, is the technology behind OpenAI's GPTs and many other AI-based apps that can do things the native ChatGPT cannot. Frameworks such as langchain and LlamaIndex have implemented this idea.
The rising interest in RAG systems stems from the challenges faced by LLMs, such as training data cutoffs and hallucinations. RAG systems help ground the responses of LLMs and can be especially useful for domain-specific queries or when dealing with private data.
Building a RAG system typically involves three components:
1. An LLM.
2. A domain-specific knowledge database.
3. A retrieval system.
The pipeline for building such a system can be seen in the following figure:
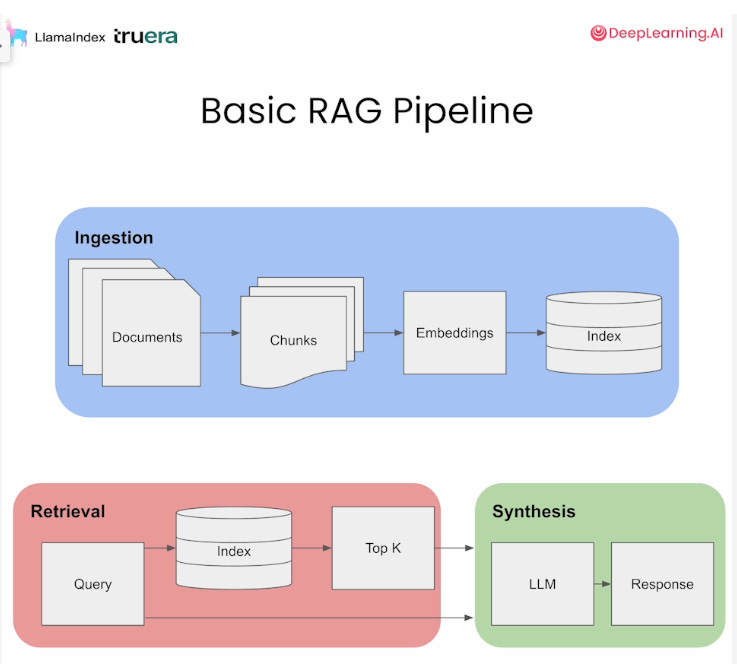
Screenshot from the RAG course by Deeplearning.ai.
Ingestion: Given the documents, the system splits them into smaller chunks, performs embeddings, and then puts them in a vector database.
Retrieval: For a user query, the system tries to identify the most relevant information from the database, and then returns the top K results (often based on cosine similarity).
Synthesis: The system feeds the user query and the returned documents to the LLM, which then generates an informed response.
For optimal functionality, each component must perform efficiently. For the LLM, you could use established models like GPT-4 or open-source alternatives. The retrieval system can be tricky, though.
Tech stacks for the retrieval system
The example above adopts the embedding technique. This approach is effective for text data because it leverages the semantic information captured by the embeddings, and vector databases can be very fast. There are actually many emerging choices, such as Pinecone and pgvector (an extension for PostgreSQL database).
However, the embedding approach faces some issues. For example, the retrieved documents are often short sentences, too fragmented for LLMs to reason based upon them. Some techniques, such as sentence-window retrieval and auto-merging retrieval, are created to mitigate this. The goal is to increase the context window for the retrieved information. The RAG course (where the screenshot was from) is dedicated to this. However, the course is deeply coupled with the LlamaIndex framework. If you only want to get a high-level understanding, just watch the introduction section and read Andrew Ng’s tweet about it.
That said, I do not think an embedding-based retrieval system is necessary. Remember, the key is to find relevant information, so any retrieval system (e.g., ElasticSearch) should work in this case. And for tabular data, I believe traditional relational databases are more suitable (wait, how can you feed tabular data to LLM? See my previous blog on this).
No silver bullet
A common misconception is that simply feeding data into the RAG system will yield accurate results because the embeddings and LLMs would magically figure things out. Unfortunately, this is not true based on my own experiences with OpenAI’s GPTs (words on the street are that GPTs are merely a side project for OpenAI and only took days to build, so one shouldn't expect too much from them) and other people's stories.
It makes a lot of sense if you think about it. If the data provided to the system is poorly structured and noisy, you can't expect the retrieval system to find the most relevant information. The final response is only as good as the information you provide to the language model. Maybe with an increased token limit, things will improve. However, I do not think it's happening soon, and that won't work for huge databases.
The devil is in the details
So what should we do? I found the experience shared by a practitioner (the original posts are in Chinese) very inspirational. The developer created a search engine specifically for developers called devv.ai. And based on my experience with the product, it works really well.
According to the developer, the key to good performance is pre-processing the data before it's inserted into the database. This involved running analysis on code, logically segmenting documentation, and applying algorithms like PageRank to websites to refine data quality. The data stored in the database and fed to the LLMs is already structured, making it much easier to search, retrieve, and process. This means that there is actually one more step in the pipeline of building an RAG system (as illustrated in the figure above).
However, data processing and construction vary case by case. And it depends on your domain knowledge and experience with the problems at hand. Unfortunately, or maybe fortunately, AI cannot replace human experts in this regard, yet.
Further reading:
https://towardsdatascience.com/a-guide-on-12-tuning-strategies-for-production-ready-rag-applications-7ca646833439
[2023-12-13] Dense X Retrieval: What Retrieval Granularity Should We Use?: The authors argue that as a retrieval unit, “proposition” is better than passage and sentence. My understanding of a proposition is a short sentence containing the document's essence. It requires some preprocessing.